



Според доклад на 404 Media, базиран на вътрешни чатове в Slack, имейли и документи, получени от изданието, гигантът в областта на чиповете Nvidia е свалял видеоклипове с продължителност „един човешки живот“ на ден, за да обучава своя изкуствен интелект.
Проектът, вътрешно наричан „Космос“, е бил създаден с цел събиране на около 80 години видео съдържание ежедневно. Бивш служител на Nvidia, пожелал анонимност, е разкрил пред 404 Media, че компанията е инструктирала своите служители да свалят огромни количества видео съдържание от платформи като YouTube, Netflix и други онлайн източници. Крайната цел била разработването на усъвършенстван видео модел, предназначен за интегриране в различни AI продукти на компанията, включително Omniverse (платформа за 3D генериране на светове), системи за автономно шофиране и технологии за „дигитални хора“.
SCOOP from @samleecole: Leaked Slacks and documents show the incredible scale of NVidia's AI scraping: 80 years — "a human lifetime" of videos every day. Had approval from highest levels of company despite staff legal/ethical concerns:https://t.co/DydXOyffUQ
— Jason Koebler (@jason_koebler) August 5, 2024
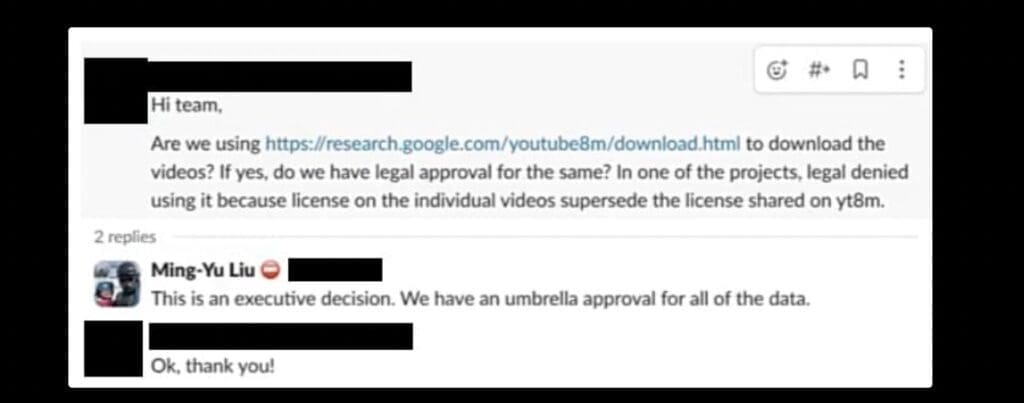
Вътрешни съобщения от Slack канал, създаден специално за проекта, разкриват, че за да изтеглят видеоклипове от YouTube, служителите са използвали програма, наречена yt-dlp, в комбинация с виртуални машини, които актуализират IP адресите, за да избегнат блокиране от YouTube.
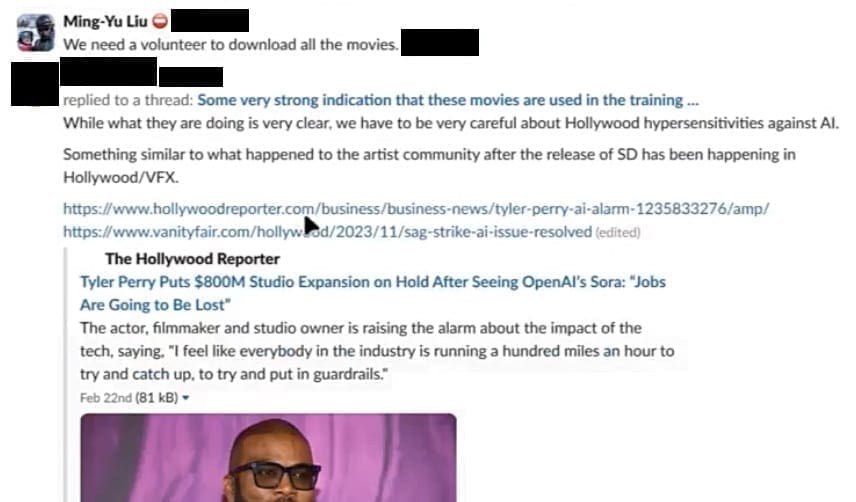
Освен видеоклипове от големи YouTube канали, Nvidia съзнателно използвала и такива, създадени специално за академични изследвания. Служителите също така са обсъждали възможността за изтегляне на множество пълнометражни филми, като един от ръководителите ги предупредил, че трябва да бъдат „изключително внимателни, предвид хиперчувствителността на Холивуд по отношение на изкуствения интелект“. Екипът е обмислял и възможността за включване на кадри от видеоигри.
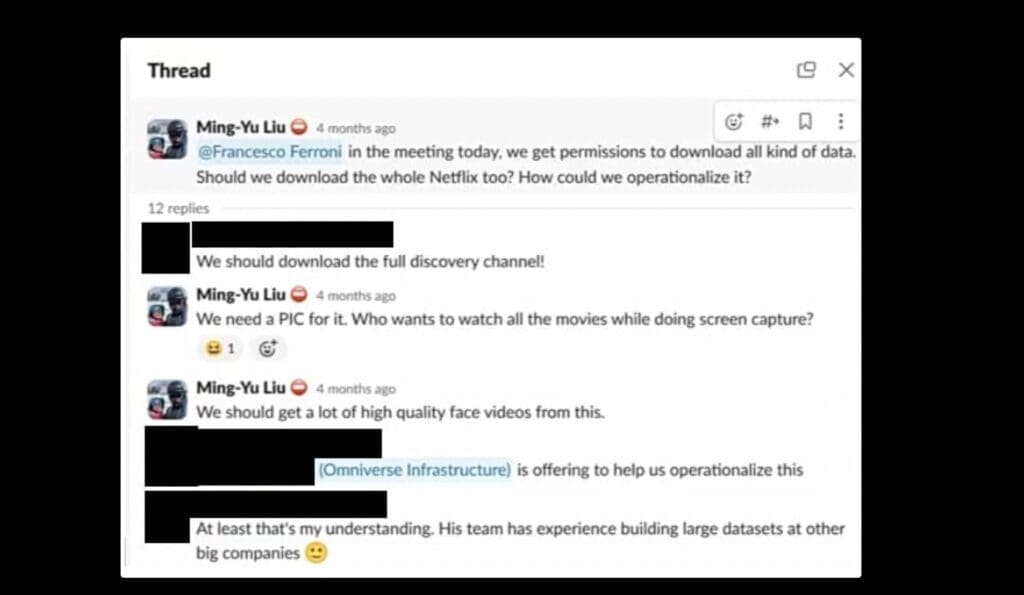
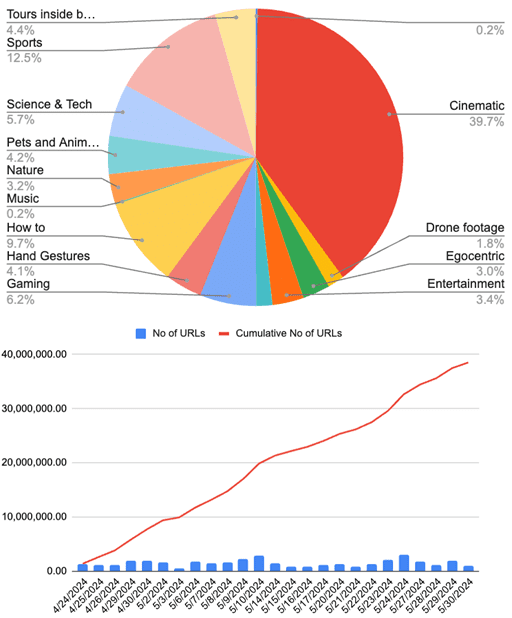
В един момент проектът е достигнал наистина огромни размери, като само за две седмици компанията успяла да свали над 100 000 видеоклипа, а в края на май екипът е разполагал с 38,5 млн. URL адреса на видеоклипове.
Естествено, мащабен проект като този предизвикал опасения сред служителите. Когато някои от тях изразявали съмнения относно законосъобразността на своите действия, ръководството ги уверявало, че разрешението идва от „най-високо ниво“ и че имат „чадър“, а темата за това какво представлява справедливото и етично използване на защитено с авторски права съдържание се считала за „отворен юридически въпрос“, който ще бъде решен в бъдеще.
Nvidia от своя страна отрича да е извършила нарушение. В изявление до 404 Media, компанията твърди, че нейните практики за обучение на изкуствен интелект са „в пълно съответствие с буквата и духа на закона за авторското право“.
„Законът за авторското право защитава определени форми на изказ, но не и факти, идеи, данни или информация. Всеки е свободен да научава факти, идеи, данни или информация от друг източник и да ги използва, за да създава свои собствени форми на изказ. Справедливото използване също така защитава възможността за използване на дадено произведение за трансформираща цел, като например обучение на модели“.
Този доклад на 404 Media следва скорошно разследване на Proof News, според което редица технологични гиганти, сред които Apple, Nvidia, Anthropic и Salesforce, са използвали хиляди видеоклипове от YouTube за обучение на своите AI модели без знанието или разрешението на създателите на оригиналното съдържание.
Последвайте ни в социалните мрежи – Facebook, Instagram, X и LinkedIn!



Споделете: