



„Това, което искаме, е машина, способна да учи от опит“, казва Алън Тюринг още през 1947 г. Десетилетия по-късно визията на бащата на компютърните науки започва да се реализира благодарение на основополагащата работа на двама пионери в областта на изкуствения интелект – Ричард Сътън и Андрю Барто.
През март тази година двамата бяха отличени като носители на наградата „Тюринг“ – престижно отличие, което се присъжда за изключителни постижения в областта на компютърните науки от 1966 г. насам.
Още от 80-те години на миналия век Барто и Сътън полагат основите на алгоритмите и математическите принципи на обучението с утвърждение (reinforcement learning – RL) – техника, която стои в основата на най-мощните AI системи днес. Примерите са многобройни: от легендарната AlphaGo, победила световния шампион по Го, през AlphaZero, която достигна свръхчовешко ниво в редица игри чрез самообучение, до най-новите „разсъждаващи“ модели като Gemini 2.5, o3 и R1, които демонстрират впечатляващи способности в математиката, програмирането и науката.
В основата на този метод на обучение стои проста, но изключително мощна идея: един „агент“ (AI система), взаимодействайки със средата – независимо дали тя е дигитална или реална – извършва действия и получава обратна връзка под формата на „награди“, „наказания“ или просто чрез числова стойност – оценка, резултат. Постепенно, чрез итеративен процес на проба и грешка, агентът се стреми да максимизира тази оценка, вземайки все по-добри решения – точно както хората и животните се учат от преживяванията си. От своя опит.
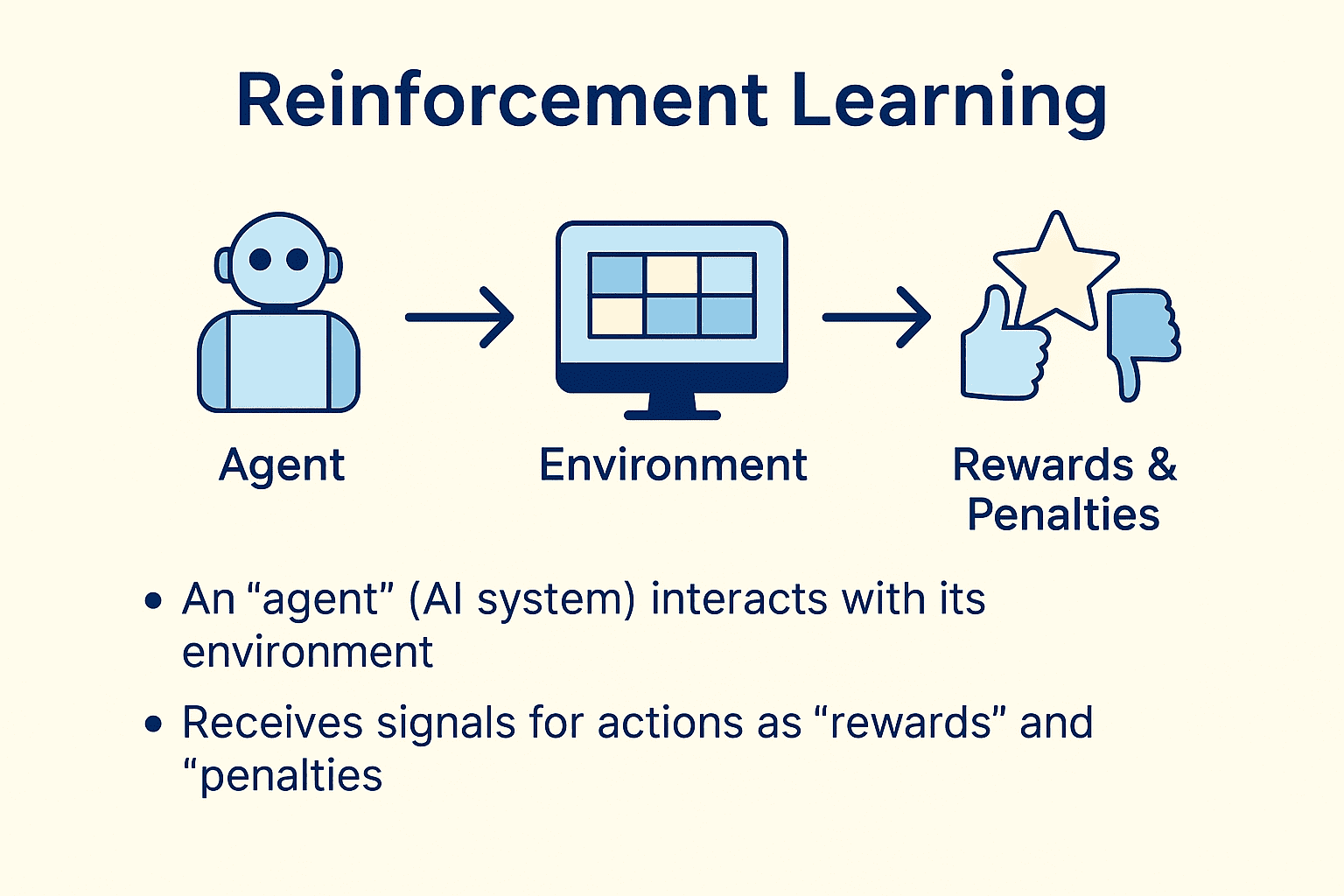
„При обучението с утвърждение агентът трябва сам да проучи как функционира светът – да опитва, да експериментира и така да научи кое е правилното действие“, обяснява Сътън пред Асоциацията по изчислителна техника (ACM). Това, според него, е същината на интелигентността – не просто пасивното следване на инструкции или механичното запаметяване на примери, а активното изследване на света чрез собствен опит. „Това е много по-мощен процес“, категоричен е той. „Интелигентността е способността да разбереш как функционира светът, а не да чакаш някой да ти го обясни.“
Ключов за този подход е балансът между „изследване“ (exploration) и „експлоатация“ (exploitation) – дилема, която Сътън и Барто идентифицират като фундаментална за всяка интелигентна система. „Експлоатацията означава да използваш това, което вече знаеш или смяташ, че знаеш“, обяснява Барто. „Но тези знания могат да бъдат непълни или дори погрешни. Ето защо е необходимо изследване – трябва да опитваш нови неща, за да обогатиш и коригираш своята база от знания.“ По думите му „тези RL системи постоянно правят точно това, често използвайки елемент на случайност, за да изпробват различни пътища.“
Този акцент върху ученето от опит е и в центъра на визионерското есе „Добре дошли в Ерата на опита“ (Welcome to the Era of Experience), публикувано от Ричард Сътън и Дейвид Силвър (ръководител на проектите AlphaGo и AlphaZero в DeepMind). В него те възвестяват настъпването на нова фаза в развитието на изкуствения интелект, която ще отключи свръхчовешки способности у машините. „Системите, обучавани единствено върху човешки данни, са ограничени и не могат да надскочат човешките възможности“, твърдят те. „Наистина ценните нови прозрения – било то теореми, технологии или научни открития – лежат отвъд настоящите хоризонти на човешкото познание и не могат да бъдат извлечени от съществуващите данни. За да ги открием, са необходими агенти, които се учат от опит.“
Последвайте ни в социалните мрежи – Facebook, Instagram, X и LinkedIn!



Споделете: