



В наскоро публикувано есе, озаглавено „Welcome to the Era of Experience“ (Добре дошли в ерата на опита), двама от най-влиятелните изследователи в сферата на изкуствения интелект – Дейвид Силвър и Ричард Сътън – очертаxa следващата фаза в развитието на AI, която според тях ще отключи свръхчовешки способности у машините.
Силвър, ръководител на проектите AlphaGo и AlphaZero в Google DeepMind, и Сътън, който наскоро спечели наградата „Тюринг“ – най-престижното отличие в областта на компютърните науки – твърдят, че светът се намира в повратен момент. „Стоим на прага на нова ера в изкуствения интелект, която обещава да постигне безпрецедентно ниво на способности. Ново поколение агенти ще придобият свръхчовешки възможности, учейки се предимно от опит“, пишат те в своя труд.
Авторите разглеждат прогреса в изкуствения интелект като процес, протичащ в три последователни етапа.
Първият е „Ерата на симулацията“ – период, в който AI агентите усвояват умения чрез взаимодействие със строго дефинирани виртуални среди. Най-ярък пример за това е легендарната система AlphaGo, която през 2016 г. победи световния шампион по играта Го. Година по-късно нейният наследник AlphaZero постигна нещо още по-забележително: без нито една човешка партия в обучителните данни, без предварителни инструкции – само чрез проба и грешка и милиони самостоятелно изиграни игри – AlphaZero разви свръхчовешки способности в трите най-сложни настолни игри: шах, Го и шоги.
Вторият етап – „Ерата на човешките данни“ – е доминиран от големите езикови модели, които се обучават върху огромни масиви от данни – книги, уебсайтове и човешка обратна връзка (reinforcement learning from human feedback – RLHF). И въпреки че изглеждат универсални – способни да пишат есета, да програмират и да обясняват квантова физика – тези системи не създават ново познание, а използват, компилират и обобщават вече съществуващо.
„Макар че имитирането на хората е достатъчно, за да се възпроизведат много човешки способности на компетентно ниво, този подход сам по себе си не е постигнал и вероятно не може да постигне свръхчовешки интелект“, пишат Силвър и Сътън, като добавят, че „скоростта на напредък, воден единствено от обучение върху човешки данни, забележимо се забавя.“
Именно тук започва третият и според авторите най-важен етап – „Ерата на опита“. Това е моментът, в който изкуственият интелект започва да се учи не от човешки примери, а от собствения си опит. Точно както децата научават за света чрез игра, експериментиране и грешки, новите системи ще трупат знания чрез взаимодействие със средата – ще наблюдават, ще опитват, ще се провалят и ще се адаптират.
Този метод, основан на обучение с утвърждение (reinforcement learning – RL), е ключов, твърдят авторите, защото „ценни нови прозрения, като нови теореми, технологии или научни пробиви, лежат отвъд сегашните граници на човешкото разбиране и не могат да бъдат уловени от съществуващите човешки данни.“
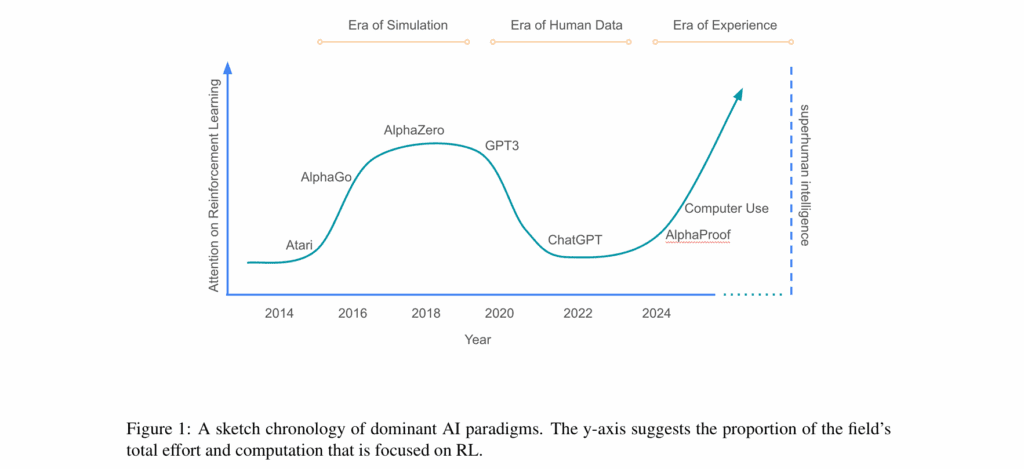
Показателен пример за този подход са AlphaProof и AlphaGeometry – две системи, разработени от DeepMind, които не само демонстрираха безпрецедентна способност да доказват сложни математически теореми, но и станаха първите AI програми, спечелили медал на Международната математическа олимпиада (IMO). Това постижение, според Силвър и Сътън, е извън обсега на системи, обучавани единствено върху човешки данни – то изисква способност за самостоятелно откриване на нови стратегии чрез опит. Последните „разсъждаващи модели“ като o3/o4-mini, Gemini 2.5 и R1 също разчитат силно на RL за постигане на впечатляващи резултати в области като математика, програмиране и наука.
„Човешките данни са ценни като изходна точка – както изкопаемите горива осигуряват първоначална енергия – но устойчивото гориво на бъдещето е опитът“, заяви Силвър в скорошен подкаст на Google DeepMind. Според него човешките знания, които се вграждат в алгоритмите, ограничават способността им да надхвърлят човешките възможности. По думите му ако искаме да достигнем нива на интелигентност, които надхвърлят човешките способности, „системите трябва да откриват самостоятелно нови неща – неща, които хората не знаят.“
Точно както AlphaZero преодоля ограниченията на AlphaGo (която първоначално се учеше от човешки партии), така и бъдещите AI системи ще трябва да се освободят от зависимостта си от човешки данни, за да разгърнат пълния си потенциал.
За да се осъществи този качествен скок в развитието на изкуствения интелект, е необходим нов тип данни – не статични и предварително събрани от хора, а такива, които се генерират динамично от самия агент, докато той взаимодейства със средата (дигитална или физическа), твърдят Силвър и Сътън. „Такива агенти ще могат активно да изследват света, да се адаптират към променящата се среда и да откриват стратегии, които никога не биха хрумнали на човек“, пишат те.
Освен това, за разлика от сегашните модели, които отговарят на въпроси в рамките на изолирани сесии и нямат памет за предишни събития, AI агентите в „Ерата на опита“ ще трябва да изградят трайна, развиваща се представа за света около себе си. Те ще се адаптират към дългосрочни цели, ще учат от последователността на събитията и ще еволюират с времето – подобно на хората. „Мощните агенти трябва да имат собствен поток от опит, който се развива, подобно на човешкия, в рамките на дълъг период от време“, обясняват Силвър и Сътън .
Според тях тези агенти ще използват различни интерфейси, специализирани инструменти или ще бъдат интегрирани в роботи, за да взаимодействат директно със заобикалящия ги свят и да се учат от него. Те ще могат автономно да провеждат научни експерименти, да тестват нови лекарства или да проектират материали – процес, задвижван от същия цикъл на опит, грешка и адаптация, който е в основата на човешкия научен прогрес. Както отбелязват авторите, „истински интелигентните агенти ще трябва да извършват действия и да получават наблюдения, които са плътно обвързани със средата.“
Въпреки обещаващите перспективи, Силвър и Сътън предупреждават, че системи, които „могат автономно да взаимодействат със света в продължение на дълги периоди от време“, крият по-голям риск. В същото време те подчертават, че един достатъчно адаптивен агент, който се учи от опит, би могъл да „разпознае кога поведението му предизвиква човешка загриженост, неудовлетвореност или тревога и адаптивно да промени поведението си, за да избегне тези негативни последици.“
В заключение, Силвър и Сътън са убедени, че навлизаме в нова фаза, в която „данните от опит ще засенчат мащаба и качеството на тези, генерирани от хора“, отключвайки „нови способности, които превъзхождат човешките“. Те вярват, че „днешната технология, с подходящо избрани алгоритми, вече предоставя достатъчно мощна основа за постигане на тези пробиви“ и че „преходът към ‘Ерата на опита’ е не просто възможен, а непосредствен“.
Последвайте ни в социалните мрежи – Facebook, Instagram, X и LinkedIn!



Споделете: